在全球 290 位开发者的协作下,Apache Doris 在 2024 年完成了 7000+ 次代码提交,并发布了 22 个版本,实现在实时分析、湖仓一体和半结构化数据分析等核心场景的技术突破及创新。
2025 年,社区将秉承“以场景驱动创新” 的核心理念,持续深耕三大核心场景的关键能力,并对大模型 GenAI 场景的融合应用进行重点投入,为智能时代构建实时、高效、统一的数据底座。
Apache Doris 2024 Review
回顾 2024 年,Apache Doris 重点聚焦于全面提升实时分析、湖仓融合分析、日志分析在实际应用场景中的效能,可将核心工作归纳为以下五个方面:
查询优化方面
- 优化器新增了多项优化规则,实现了统计信息的高效自动收集,具备了自适应执行并发度的能力。
- 在物化视图的构建以及透明改写方面,投入大量精力深入优化,极大提升查询效率。
- 对 ARM 架构包含 AWS Graviton 处理器、华为鲲鹏处理器进行深入性能优化。
存储优化方面
- 持续提升导入稳定性,尤其在高并发、小批量以及 Routine Load 的健壮性等方面。
- 探索更为复杂的数据处理场景,如对多语句事务的支持等。
半结构化分析方面
- 提升 VARIANT 数据类型成熟度,成为业界最高效的 JSON 格式数据处理方案。
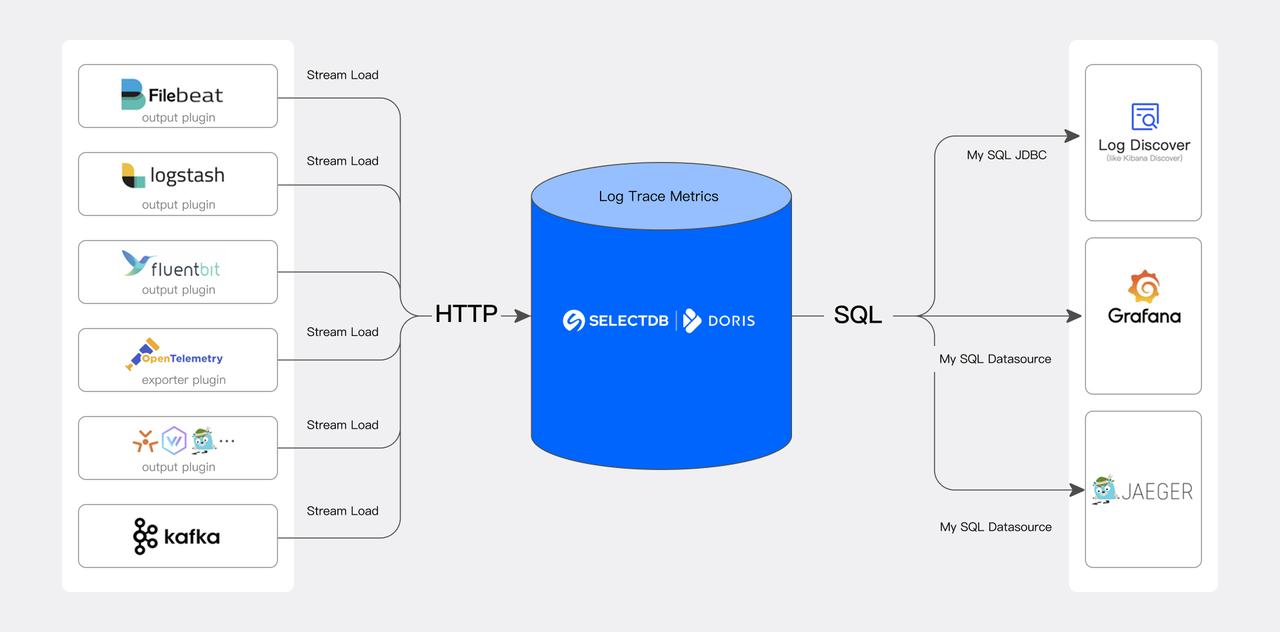
- 日志存储与分析场景的用户量增长迅猛,有上百家中大型企业用户采用 Doris 替换 Elasticsearch、Clickhouse、Loki 来应对日志场景。
Lakehouse 湖仓分析方面
- 作为 Doris 重点支持的场景之一,2024 年针对 Hive、Iceberg、Hudi、Paimon 进行了大量兼容和深度优化工作,性能和稳定性有明显提升。
- 进一步完善 SQL 方言的兼容支持,以便于用户能够实现平滑迁移,在多个大型用户实际场景中,兼容性高达 99%以上。
云原生存算分离方面
- 在 3.0 版本中,Doris 全面支持了存算分离架构,将云原生理念引入开源社区,进一步增强了无服务化以及按需弹性场景的支持能力 。
2024 年除了新功能的开发和架构性能优化,我们也花费大量时间进行质量保障,包含深入 Reivew 之前的功能设计,以确保稳定性及可扩展性;大量的黑盒、白盒测试;仿生产系统长稳压测;混沌测试等。我们希望在保持 Doris 创新力的同时,依然能够更加聚焦在 Doris 核心功能与稳定性上,确保用户、客户能够获得真正的收益和价值。
Apache Doris 2025 Roadmap
2025 年,社区将秉承“以场景驱动创新” 的核心理念,持续深耕三大核心场景的关键能力,并对大模型 GenAI 场景的融合应用进行重点投入,为智能时代构建更加实时、高效、统一的数据底座,工作重点将围绕以下几个关键方面展开:
- 深耕三大核心场景: 进一步聚焦实时分析、湖仓分析以及半结构化数据分析三大核心分析场景**,**并在这些方向上持续深耕细作,不断提升性能与应用效果,为用户提供更为优质、高效的分析服务。
- 大模型 GenAI 场景融合应用: Doris 社区始终坚持创新、拓展技术边界。2025 年将在与生成式人工智能(GenAI)融合应用上进行重点投入,打造适配 GenAI 时代的数据基础设施。本周我们在 Webinar 直播活动中介绍了多款热门 AI 大模型与 Doris 的融合应用。
- 安全可靠的云原生: 2025 年,云原生方向的工作重点将聚焦于数据安全、ETL 易用性和存算分离关键方面展开。
- 加强数据处理能力: 加强批量数据处理和增量数据处理能力,为数据加工、ETL 等场景提供更高性价比解决方案,满足用户日益增长的复杂数据处理需求。
- 进一步提升稳定性: 从技术优化到流程把控,全方位保障 Doris 在运行过程中的稳定性,降低风险,为用户提供更加可靠的产品与服务。
- 开放的社区生态: 积极开展更多与各方的社区合作,完善社区支持工作,为社区成员提供更加全面的服务,无论是技术支持、经验分享或是资源支持等。
01 深耕三大核心场景
实时分析
实时分析场景是 Doris 的立足之本,致力于打造速度最快且最具成本效益的分析型数据库。2025 年将持续优化 Doris 查询引擎、查询优化器,使其在无论单表查询还是复杂的多表关联查询,均能游刃有余、展现卓越的性能。
在查询引擎方面, 将继续强化 Doris 在自适应能力、通用场景支持以及资源管控等方面的能力。并重点从以下几个方向着手:
- 在 TopN 加速和延迟物化方面,Doris 目前已初步支持这些功能,但应用范围有限。未来将计划全局泛化,使其在复杂的多表关联场景中也能发挥优化作用,从而进一步提升查询性能。同时将引入用户可管理的全局字典能力,帮助用户在维度关联等场景下显著提升性能。
- 对 ARM 架构的深度适配将是今年的重点任务之一。2025 年计划为不同型号的 CPU 定制向量化库,以进一步提升 Doris 在各类 ARM 机型上的运行性能。
- 在资源管理方面, 2025 年将实现管理的统一性和可观测性。目前,Doris 的资源管理主要针对用户请求,如查询和导入。后续计划将把所有内部任务(如 Schema Change、Compaction 和统计信息收集)纳入统一的资源管理框架,并统一管理这些任务在资源受限情况下的行为,包括取消和排队等操作。还将对资源调度机制本身进行优化,包括引入多优先级队列调度等新技术,以提升混合负载场景下各执行任务的可预期性。此外,将增加更丰富的系统表和监控指标,以全面展示 Doris 运行细节,提升 Query Profile 的可视化程度和可理解性。
在查询优化器方面, 查询优化器在数据库技术中占据着重要地位,被誉为数据库领域的“明珠”。2025 年,Doris 的查询优化器将着重于规划性能、质量管理和可观测性这三个关键方面:
-
规划性能: 规划性能的优劣直接影响到集群的吞吐能力、QPS 以及实际使用体验。
- 简单查询场景:对“
SELECT * FROM table WHERE”这类查询语句,采取特殊优化措施,通过剔除不必要的改写规则、加速分区裁剪等操作,减少查询过程中的迭代次数,以提升系统的响应速度和处理效率。 - 复杂多表关联场景:在涉及十几张表甚至更多表的关联查询场景中,优化查询规划时间,规划时间缩短至秒级以下,提升复杂查询的执行效率。
- 简单查询场景:对“
-
规划质量管理:
- 引入基于历史统计信息的查询规划(HBO)。无论是基于代价的优化器(CBO)还是规则的优化器(RBO),都会遇到信息估算不准确问题。传统的统计信息收集方式虽能解决部分问题,但其收集成本高、覆盖范围和准确性有限。基于历史统计信息的规划方法则具有更强的场景适配性,能根据用户历史查询场景和数据特点准确预测和规划,提升查询规划的质量。
- 建立完善的 Plan 管理机制。在特定业务场景下,用户可以通过注入 Hint 获取最优查询规划并保存自定义的 Plan 规则,当再遇到类似查询需求时,可直接复用。未来将支持对指定 Plan 进行固化,避免系统升级或者数据变更后出现 Plan 漂移,确保查询规划的稳定可靠。
- 探索 Plan 候选集自动优化机制。通过让系统不断学习和分析历史查询数据及执行结果,自动调整优化 Plan 候选集,使系统在面对复杂查询场景时能够更智能地选择最优查询规划,持续提升系统整体性能。
-
规划可观测性:
- 2025 年将提供丰富机制,如查询规划的回放、在线 Tracing 等功能,帮助用户更好地观察和理解查询规划的迭代过程。用户可清晰了解查询优化器各阶段采取的策略及性能表现。这将有利于及时发现和解决查询过程中出现的问题,提升用户对 Doris 的使用体验。
湖仓一体
在 2025 年,社区将重点推进开放湖仓生态的建设,打造统一的分析入口,以高效便捷地实现湖仓数据处理与分析,全面提升用户体验。今年,我们的重点工作将集中在以下几个方向:
- 完善开放湖仓生态: 随着 Iceberg 、Paimon 、Hudi 等生态迅猛发展,Doris 现已对接完善。2025 年除持续优化 DDL(数据定义语言)和 DML(数据操作语言)操作外,将密切关注湖格式的最新发展动态及其他主流开放湖格式,及时跟进包括新的数据类型、数据格式更新,并及时对接兼容,为用户提供更加流畅的数据集成能力。
- 优化物化视图: 物化视图在湖仓融合过程中的重要桥梁,可通过透明改写实现查询加速,也可支持湖上数据加工操作。Doris 现已全面实现对 Hive、Iceberg、Hudi 和 Paimon 的物化视图分区增量更新和改写能力支持。后续将进一步增强物化视图的可操作性,例如实现逻辑视图与物化视图之间的转换及物化视图的智能推荐等。同时,还计划尝试暴露数据血缘相关信息,帮助用户更好地将 Doris 集成到其数据平台中,提升整体的数据处理效率和数据管理水平。
半结构化数据分析
在 2025 年,半结构化数据分析将实现重大突破,从单一日志分析场景全面升级为可观测领域的行业标准。 今年将加大在性能优化、成本控制以及生态建设方面的投入,构建业内领先的可观测性产品基础设施。
- 在全文索引能力方面,2025 年将支持多语言分词器,如支持 IK 和 Unicode ICU 分词器,并提供用户自定义字典功能,增强分词器的灵活性和适配性。同时,计划在存算分离场景实现索引的增量构建,提升数据处理的效率,并在确保索引性能的前提下,降低存储资源的消耗,以更低的成本实现高效数据分析。
- 在系统可观测性层面,重点加强对索引相关信息的展示,包括索引的构建过程、命中率、过滤率等关键信息,以此更清晰地展示索引的运行状态,用户可更有效地管理和优化索引,提升系统的整体性能与稳定性。
- 在 Variant 列类型支持方面,2024 年以来,众多湖格式也开始支持 Variant 列类型,充分证明其在半结构化数据处理中的优势。Doris 作为这一领域的先行者,将进一步拓展 Variant 列类型的能力,例如,支持数万列规模宽表,以应对大规模数据存储和处理;对稀疏列进行优化,提升数据存储和检索的效率;支持更灵活地控制子列的展开范围,能够根据具体需求更精准地操作和管理数据;同时,还将支持对指定子列构建索引,进一步提升数据查询的速度和准确性、降低索引存储的成本。
- 在生态合作方面, 对接更多的日志传输组件,如 iLogtail、Vector 等。并与相关社区积极联动,共同探索和推出可观测性方面的最佳实践。通过不断优化和完善,提升对日志数据的处理能力和效率。
总体而言,我们的愿景是将 Doris 打造成可观测性领域的行业标准,以更低的成本、更卓越的性能,为广大用户提供更优质、高效的半结构化数据的存储与分析服务。
02 GenAI 场景的融合创新
2025年,Apache Doris 将持续增强对 AI 场景的支持能力:
- Apache Doris 2.1 版本基于 Arrow Flight 实现了高速数据传输通道,使数据科学和机器学习的软件可以直接从 Doris 中高速读取数据进行建模分析。
- 在湖仓融合分析场景中,Doris 可以作为 Lakehouse 的计算和查询引擎,利用其高效的性能,加速大规模数据的预处理,并将结果写回 Lakehouse,以支持后续的模型训练等 AI 场景使用。
- Doris 还可以作为特征存储系统,服务于智能推荐、风控系统等场景。
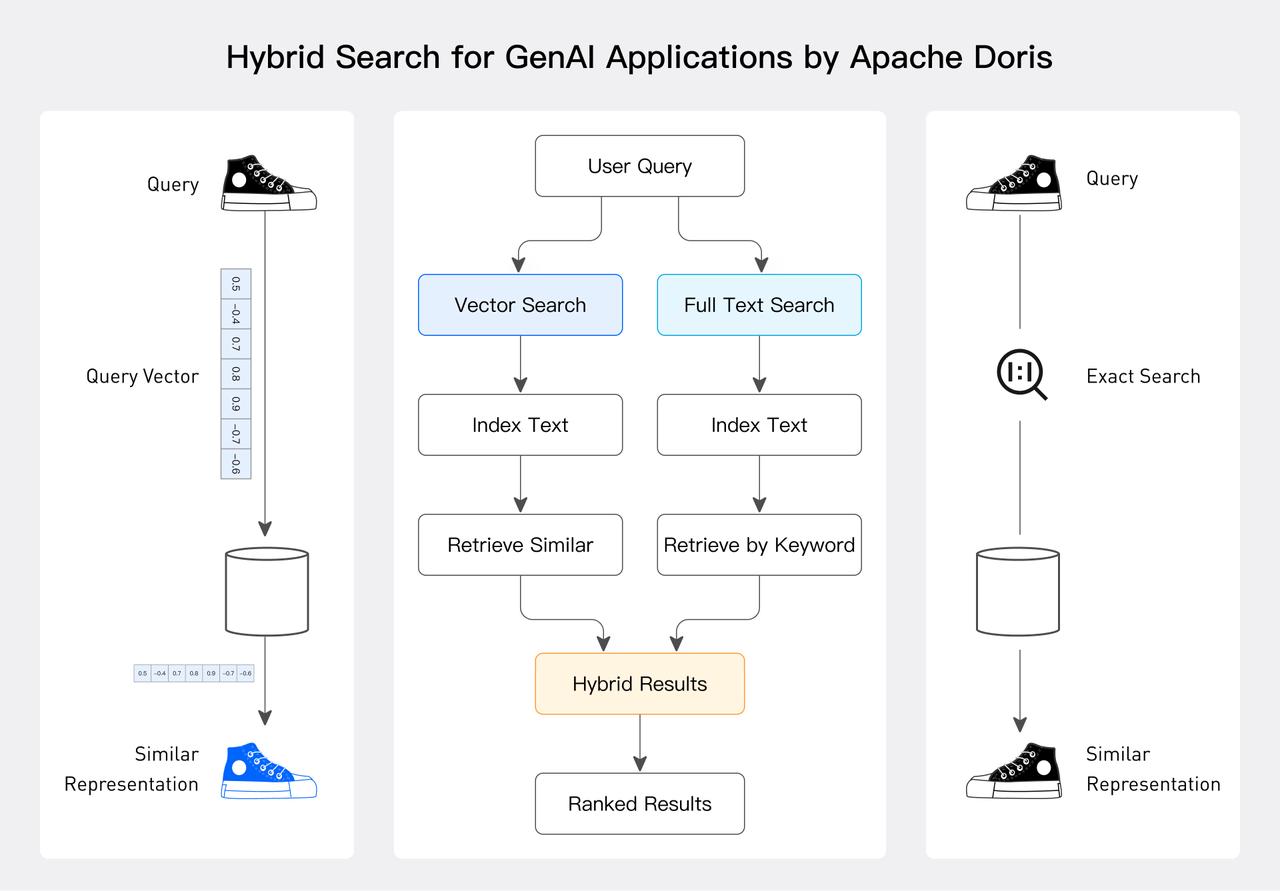
- 在 GenAI 场景中, RAG 是提升准确性和减少幻觉的关键技术,RAG 通过混合检索来提升效率和准确性,常见方式包含向量检索、全文检索、知识图谱检索等,相比于使用多套系统,如果单一系统能够支持多种检索,将大幅提升效率、简化架构并减少数据冗余。Apache Doris 自 2.0 开始支持完善的全文检索能力,目前正重点支持向量索引的能力,预计 2025 年 2 季度在社区发布(部分互联网大厂已在大规模上线验证中)。 届时,Doris 将从高效分析引擎扩展为高效的分析和混合检索引擎,成为智能时代实时、高效、统一的数据底座。
- 2025 年,Apache Doris 也将加强 NL2SQL、Data Agent、MCP 等应用的布局。近期,我们在 Webinar 直播活动中介绍了多款热门 AI 模型与 Doris 的融合应用,包括利用 DataAgent 实现智能数据代理、通过 RAG 增强知识检索以及结合 ChatBI 打造自然语言交互分析,同时介绍了 Doris MCP Server 的构建及实现。点击查看直播回放及资料
03 安全可靠的云原生
2025 年,云原生方向的工作重点将聚焦于数据安全、ETL 易用性和存算分离等关键方面展开。
- 在数据安全与集群高可用上
- 跨集群复制(CCR)功能:增加主动的主备切换等关键能力。同时,我们正在筹备详细的 CCR 实践教程,帮助用户在实际应用中实现跨地域集群的高可用性,有效应对故障和异常,确保数据安全和业务连续性。
- 数据加密:随着 Doris 在金融、政企等行业的广泛应用,以及海外用户对数据合规性和敏感性要求的提升,透明数据加密(TDE)的需求日益增强,这方面工作很快完成。
- 在 ETL 易用性上
- 临时表功能:由腾讯公司贡献的临时表功能,此前已在 GP 数据库中广泛应用。借助临时表,用户可以更便捷地对数据进行临时加工和验证,同时无需担心数据清理等繁琐操作,显著提升数据处理的效率和灵活性。
- 多语句写入事务功能:该功能允许用户在同一个写入事务内对多张表进行 ETL 操作,并确保这些操作原子生效,从而保障数据的一致性和完整性。这一功能为用户在构建 ETL 作业时提供了更高的灵活性,能够更好地满足不同业务场景下的数据处理需求。
- 存算分离:
- 2024 年,Apache Doris 3.0 版本已支持存算分离全新架构,2025 年将对这一场景进行持续优化和打磨,将存储层打造成一个坚实可靠的数据基座,为 Doris 之上的各种功能提供强有力的支撑和保障。具体优化包括冷数据的优化处理、制定更灵活的 Cache(缓存)策略等。例如,在读写分离场景下,支持将写集群中实时写入的数据快速预热到读集群的 Cache 中,从而提高数据的新鲜度和系统整体性能。
04 加强数据处理能力
2025 年,社区将加强批量数据和增量数据处理能力。
- 在批量数据处理领域, 如何利用有限资源处理更大规模的数据是一个关键问题。据 Snowflake 的统计,其平台上 80% 的任务属于 ELT 任务,而仅有 20%的任务来自在线查询。需要注意的是,这些 ELT 任务所处理的数据规模通常为 TB 级别,而非 Hive 或 Spark 所面对的超大数据场景。因此,通过数据溢写、分批次调度以及资源隔离管控等技术手段,能够在实时数据处理框架下,满足绝大多数用户在 ELT 场景中的需求。因此,批处理领域将成为社区持续探索的重要方向。
- 在增量数据处理领域, 目前仍然在规划中,包括 Binlog、实时增量物化视图等功能,2025 年也将持续探索创新,以满足用户日益变化的数据处理需求。
05 进一步提升稳定性
2025 年,将从以下三个维度全面提升 Doris 的稳定性:
- 优化发版规则: 2025 年将继续对 2.1 和 3.0 这 2 个版本持续迭代,上半年将发布 3.1 版本,并预计下半年成为最新稳定版本。今年起,我们优化了三位版本的迭代规则,严格限制新功能和非必要优化,仅允许必要的 Bug 修复。3.1 版本将基于 3.0 稳定版本分支迭代,而非直接从 Master 分支拉取,且仅并入经过全面测试的必要功能和优化,力求缩短 3.1 的稳定周期。此外,今年还会发布 4.0 版本,推出面向 AI 时代的数据基础设施。
- 强化代码审查: 对 PR 模板进行了调整,要求提交者提供更加详尽的描述,包括是否进行了测试、是否存在行为变更、是否配备了相应的文档等内容。目前,社区正在筹备引入强制单测覆盖率准入机制,以进一步规范开发流程。希望通过这些机制,减少人为疏忽,确保代码质量,从而提升 Doris 的整体稳定性。
- 加强测试环节: 除社区流水线的基础测试外,还新增了丰富的测试场景,如压力测试、混沌测试以及专项测试,通过全方位、多维度的测试,进一步夯实 Doris 的稳定性基础。
结束语
以上,就是 Apache Doris 2025 年 Roadmap 的完整介绍。在此,感谢每一位支持 Apache Doris 社区的开发者及使用者,感谢你们共建与支持。我们热忱欢迎更多朋友加入社区,共同迎接挑战。如果您希望参与开发或进行技术交流,可通过下方二维码加入社区交流群,如有任何使用及发展建议,均可反馈。

