摘要:本文整理自 SelectDB 技术副总裁、Apache Doris PMC Chair 陈明雨老师在 Flink Forward Asia 2024 行业解决方案(二) 专场中的分享。内容主要分为以下三个部分:
Introduction: What is Apache Doris
Lakehouse Solution: Apache Flink + Paimon + Doris
Ecosystem: Doris Community & Clould
概述
什么是 Apache Doris
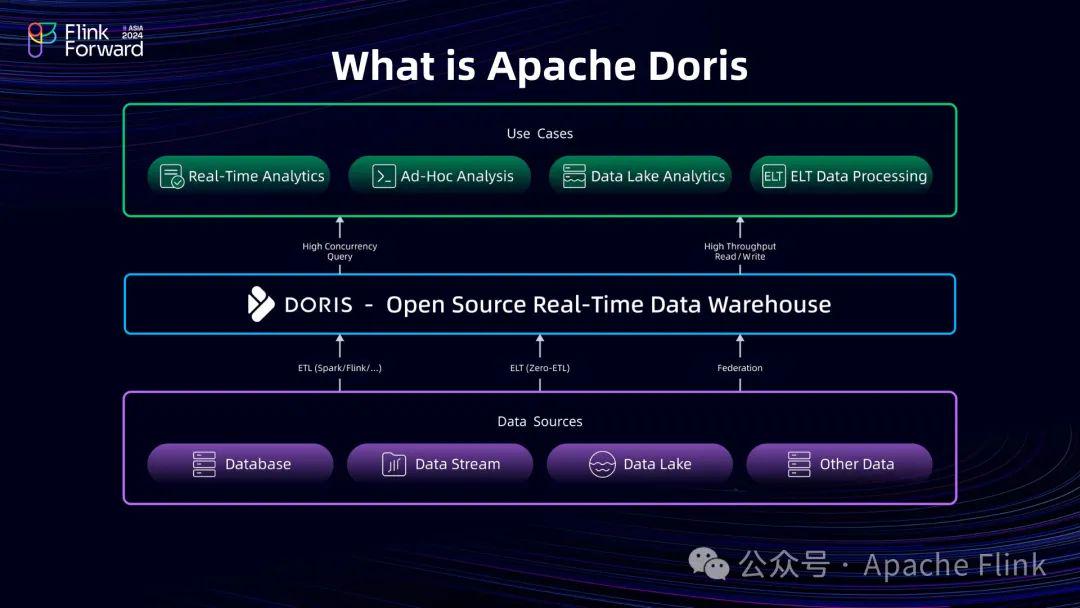
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
上图是 Apache Doris 在大数据架构中的定位。Doris 的上游是数据源层,包括高业务数据库、数据流、数据湖等。Doris 通过两种方式对接这些数据源。
第一种方式是通过 Spark、 Flink 等流批处理系统对上游数据进行采集加工后,导入到 Doris 中进行存储。Doris 作为一个完整的数据库系统,可以直接对外提供服务。第二种是通过 Doris 自身丰富的数据源连接器直接连接这些数据源,从而可以通过 SQL 对这些数据进行直接的加工处理,进行包括 Zero-ETL、联邦数据查询等任务。
最上层是业务应用,Doris 可以支持包括实时报表、实时决策、交互式探索分析、湖仓查询加速以及日志与事件分析等多种应用场景。
为什么选择 Apache Doris

相比于其他数据分析系统,Apache Doris 在性能、易用性和多场景支持方面有突出表现,这也是为什么很多用户选择 Doris 的原因。
- 性能方面,借助向量化查询引擎、Pipeline 执行模型、列式存储、二级索引、物化视图、智能缓存等技术,Doris 无论在宽表场景如 ClickBench,还是在 TPCH、TPCDS 等复杂查询场景中都能保持领先优势。
- 易用性方面,Doris 对系统维护方和使用方都非常友好。Doris 可以方便的部署在裸金属、云虚机、K8S 等环境中,并提供副本均衡、修复等多种自动化的分布式系统管理能力。此外,Doris 支持 MySQL 协议和标准 ANSI SQL,极大地降低了用户的接入和学习成本。
- 场景多样性方面,Doris 可以支持包括日志分析、实时多维分析、用户画像、湖仓查询加速、联邦分析等多种场景,帮助用户使用单一引擎在不同场景中获得一致的数据分析体验。
Apache Doris 典型应用场景
接下来看一下 Apache Doris 的三个典型应用场景。
首先是典型的实时多维分析场景。这里我们通过标准测试集直观的展示 Doris 的性能表现。首先是有 Clickhouse 公司公开的 ClickBench 测试集,这个测试集用于通过 42 个精心构造的聚合查询对一张 100列左右的宽表进行查询。可以看到 Doris 的性能仅次于内存数据库和经过调优后的 Clickhouse。而在以 TPCH 和 TPCDS 为代表的复杂关联查询场景下,Doris 相比同类产品也具有明显的性能优势。当然,标准 Benchmark 并不能代表实际的生产体验,所以也欢迎大家下载 Doris 进行实际测试。
第二个大的场景是日志分析场景。Doris 的日志分析解决方案目前已经非常成熟了。很多用户使用 Doris 每天存储和处理几十 TB 的增量数据。相比于 Elasticsearch,Doris 无论在存储成本、写入性能还是查询性能上,都有显著的优势。在技术细节上,Doris 提供了倒排索引和全文检索能力,并且提供 Json、Variant 等丰富灵活的半结构化数据类型支持。很多用户将原有的日志系统从 ClickHouse 或 Elasticsearch 迁移到 Doris 上,达到降本增效的效果。
最后一个场景,也是本次分享的重点,湖仓分析场景。Doris 现在支持的 Paimon 、Iceberg 等所有的主流湖仓系统的连接器。并且 Doris 针对湖仓场景进行了大量深度优化,包括 IO、缓存、查询调度等等,旨在为用户提供实时高效的开放湖仓数据分析体验。这里我们展示了在基于阿里云 OSS 存储,在 1TB 的 TPCDS Paimon 数据表上,Doris 的总体查询性能是 Trino 的 3 倍。
核心特性:湖仓一体
多维分析、日志分析和湖仓分析是 Doris 的三大应用场景。接下来我将主要介绍 Doris 在湖仓分析场景的应用和解决方案。
Data Warehouse & Data Lake
在介绍解决方案之前,我们先回顾下 Lakehouse 的由来,以及数据湖和数据仓库的区别。
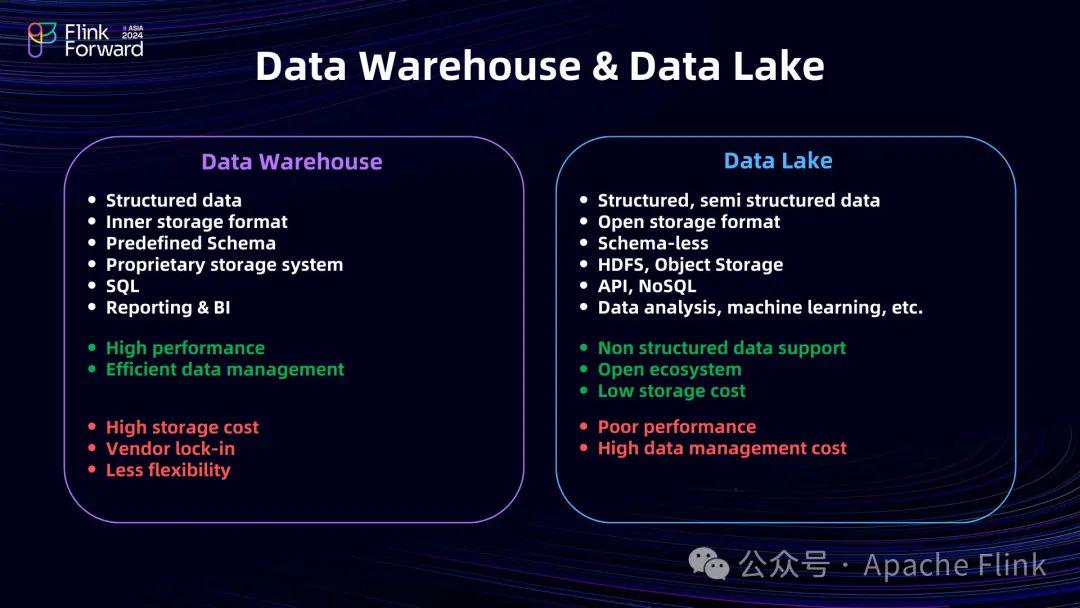
数据仓库主要处理结构化数据,使用内部存储格式和预定义模式,依赖专有存储系统,支持 SQL 查询,常用于报表和商业智能(BI)。其优点是性能高、数据管理高效;缺点是存储成本高、容易被供应商锁定且灵活性较低 。
数据湖能够处理结构化和半结构化数据,采用开放存储格式,支持 HDFS、对象存储等共享存储服务,适用于数据分析、机器学习等场景,有开放的生态系统,存储成本低。但它存在性能较差、数据管理成本高的问题 。
而 Lakehouse 则是两者的结合,融合了数据仓库和数据湖的优点,在提供统一的共享数据服务的同时,还解决了数据质量问题、管理问题,并能够提供多样化的分析负载。
Lambda & Kappa 架构
数据仓库和数据湖的建设离不开 Lambda 和 Kappa 这两种经典的数据处理架构。

通常来说,数据处理架构分为三层。
**第一层是数据源层。**以 Kafka 为典型代表,对多个数据源进行统一数据采集和存储。
第二层是数据处理层。在 Lambda 架构中,数据处理层被划分为两个层级,分别为 streaming Layer(流处理层)以及 Batch Layer(批处理层)。这种分离主要是基于以下业务需求:一方面,需要实时数据以保证数据的新鲜度,用于实时数据的处理和展示;另一方面,历史数据也不能缺失,历史数据要用于回溯、历史数据分析以及为上层决策提供支持,同时还需要一个 Back Layer(回溯层)进行数据统计。然而,这也会引发一些问题,例如,虽然它满足了两种场景的需求,但是整个操作过程非常复杂,两条流的数据如何保持一致成为难题,各种校验和对齐工作使得数据一致性很难得到保证。之后,又出现了 Kappa 架构。Kappa架构并非完全替代Lambda架构,而是一种面向实时数据处理的优化方案。Kappa架构的唯一区别在于删除了 Batch Layer。在早期架构中,无法实现流批的统一处理,所以 Kappa 架构只能通过舍弃一些历史数据的访问能力,来简化系统并解决数据一致性问题。Lambda 和 Kappa 架构本质上是一种融合流数据、批数据以及实时数据和历史数据的解决方案。
第三层是数据服务层。通过不同的查询引擎对外提供数据分析服务,比如通过 Hive 进行 ETL 数据处理,或通过 Presto 进行交互式分析。
湖仓一体挑战
随着 Flink、Paimon 等流批一体的计算和存储系统的出现,这两套方案也逐渐融合成了现代化的实时湖仓架构。实时湖仓架构面临三大挑战。
第一点是湖仓融合,把这两类系统优势整合在一起,中间可能会有折中或者权衡,目的还是需要把优势结合在一起提供一个统一方案。
第二点是 Batch 和 Streaming 融合,怎么把流和批结合在一起,不光计算层面的流、批,包括存储层面的流、批。计算层面可以有流处理的语义和批处理的语义,存储层怎么接这样的数据也是一个挑战。
第三点是 Data Changes。如果完全面向流数据,整个历史数据甚至包括实时数据的改变在之前的解决方案中都很难得到满足。
Doris + Flink + Paimon 构建湖仓一体
接下来介绍基于 Doris 、Flink 和 Paimon 的湖仓一体解决方案。
首先,数据源层依然是各种业务数据库、Binlog、日志、埋点数据流等。主要变化发生在数据处理层和数据服务层。
数据处理层通过 Flink 和 Paimon 融合了 Streaming 和 Batch Layer。 Flink 在计算层面实现批流融合,它能够高效地处理批量数据和流式数据,为数据分析和计算提供强大的支持。用户既可以通过 Flink CDC 将上游数据直接导入到 Doris 存储中,也可以通过 Flink 进行处理后入湖(Paimon)。而 Paimon 则在存储层面进行批流融合,使得存储系统能够同时适应批量数据和流式数据的存储需求。通过这样的分层架构,能够非常出色地将实时数据和批量数据进行统一整合。如此一来,仅仅一个流就既可以用于历史数据分析,也能够进行实时数据分析。这极大地提高了数据分析的灵活性和效率,使得用户可以更加便捷地对不同类型的数据进行深入分析和挖掘。
数据服务层由 Doris 承接。 Doris 针对 Paimon 数据进行了非常多的优化,能够帮助用户进行快速的直接数据分析,后面会展开其中的技术细节。其次,基于 Doris 的异步物化视图能力,用户可以 Doris 内部对 Paimon 数据进行分层加工,或者通过透明改写能力利用物化视图对特定模式的查询进行加速。同时,除了 MySQL 协议外,Doris 还支持基于 Arrow Flight 的 ADBC 协议。相比 MySQL 协议,ADBC 更适合高性能的数据传输,在 AI 和机器学习场景下,能够快速的传输大量的数据。此外,Doris 也支持了非常丰富的统一元数据管理服务(Unified Catalog),包括阿里云 DLF,AWS Glue 等。无论是 Paimon 还是 Doris,在接入统一的元数据管理之后,能够极为便捷地进行数据口径一致性管理以及权限管理等操作,这些均可通过 Catalog 来完成。如此一来,便能够确保用户既可以享受到湖的批流一体能力,又能够体验到仓的极速查询体验。
接下来我们先介绍下 Doris 和 Flink CDC 结合的场景。
Doris 社区提供了 Flink Doris Connector 组件,这个组件封装了Flink CDC 能力,提供从TP 到 AP 的端到端的解决方案。
- 自动同步建表语句 DDL:对上游数据新增了一个表,通过一些规则和映射可以直接把 DDL 同步到Doris中自动建表。
- 自动感知 Schema Change:通过 Doris 的 Light Schema Change 功能可提供快速表结构变更的能力。例如,若上游频繁进行加列和减列操作,下游的 Doris 能够在毫秒级完成表结构变更,不会出现因上游稍有变动,下游就需耗费一小时进行历史数据转换的情况。
- Exactly-Once 数据更新和同步:Doris 通过主键模型能够很好的支持数据更新。通过两阶段提交语义和导入 Label 机制,保证多个子任务或者子流的数据能够原子性生效以及导入幂等性,避免数据一致性的问题。从而完整的实现端到端的 Exactly-Once 数据同步语义。
- 多流 Join:Doris 的部分列更新(Partial Update)能力,可以将来自不同数据流的数据自动进行宽表拼接,不仅节省了 Flink 端的计算资源,也使整个系统的写入性能得到提升。
接下来就是基于 Apache Doris + Paimon 的湖仓加速的场景。
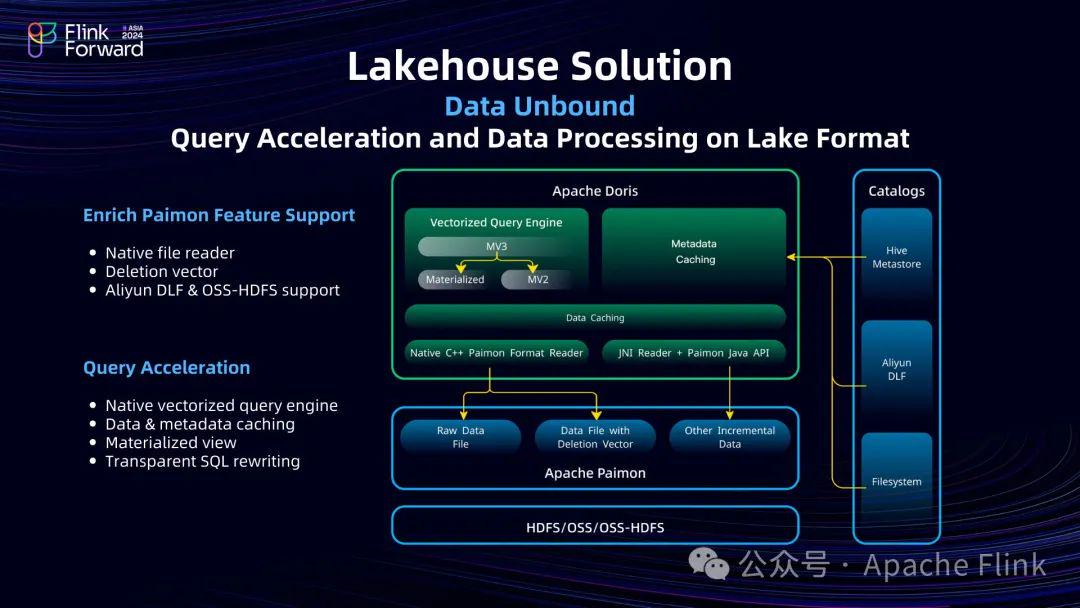
Doris 社区自 Paimon 0.5 版本开始接入 Paimon 生态,并实时跟进 Paimon 的最新特性,比如 0.6 版本中的 Read Optimize 可以直接通过 Native File Reader 读取 Paimon 表中已经合并后的 Parquet/ORC 文件。以及 0.7 版本中的 Deletion Vector 支持等等。目前已经支持到了最新的 1.0.1 版本。
在性能优化方面,Doris 在远程 IO、数据缓存、元数据缓存方面都做了非常多的工作。
- IO优化:针对 HDFS 或者对象存储系统的特性,Doris 实施了涵盖小 IO 合并、IO 预取、延迟物化等诸多优化举措,助力用户在未命中缓存的情况下读取远端数据时,依旧能够实现较为良好的吞吐效果或者较低的延迟。
- 数据缓存:Doris 内置有轻量的本地数据缓存功能,能够将远端存储的热点数据块缓存至本地高速磁盘。对于热点数据的查询,若命中缓存,其查询性能可与 Doris 内表格式相媲美。
- 元数据缓存:无论访问 DLF 还是其他元数据服务,远端访问的稳定性往往难以得到切实保证。鉴于此,团队在 Doris 内部实施了元数据缓存操作,对分区信息以及文件列表信息进行缓存,从而避免频繁进行文件列表操作,以实现大表能够在毫秒级时间内返回查询计划或者所需访问的文件列表等内容。
- 物化视图:Doris 支持基于 Paimon、 Iceberg、Hive 等表格式构建异步物化视图,并支持分区级别的增量构建。物化视图使用 Doris 内部格式存储,用户可以直接查询物化视图的数据获得最佳的查询能性能。也可以通过透明改写能力,在不改变原始查询语句的情况下,由 Doris 的查询优化器将查询自动路由到最合适的物化视图上,进行透明查询加速。
下图展示了 Doris 在 TPCDS 1TB 规划下,和 Trino 相比,查询 Paimon 表的性能对比。
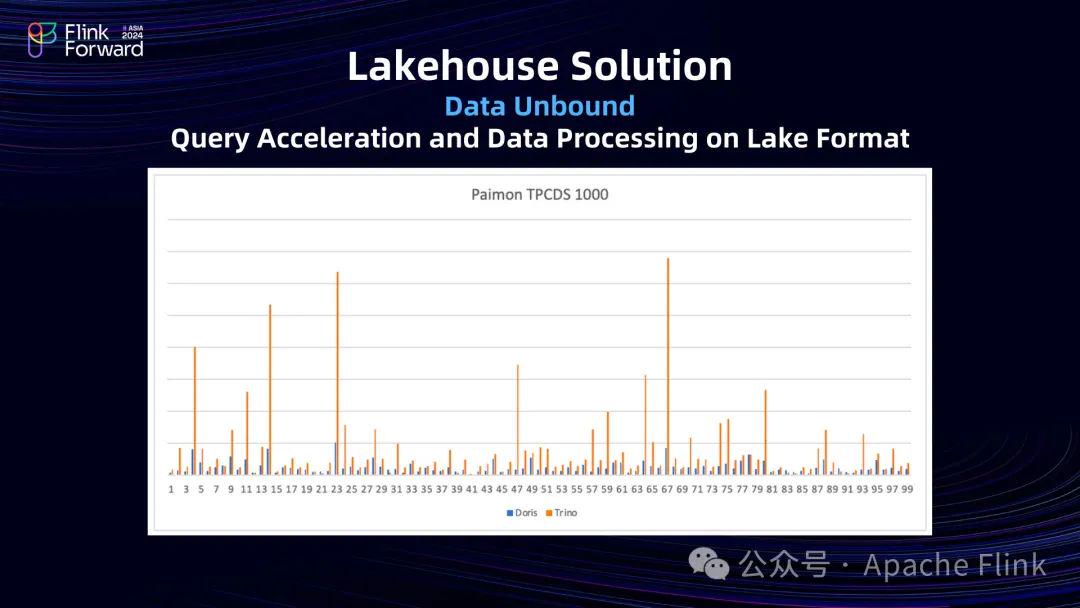
数据以 Paimon 表格式存储在阿里云 OSS 上,并使用阿里云 DLF 作为元数据服务。可以看到,相比于 Trino,Doris 在整体查询性能上有 3-5 倍的提升。
生态集成
最后,再简要介绍下 Doris 的原生和社区生态。
Apache Doris on Cloud
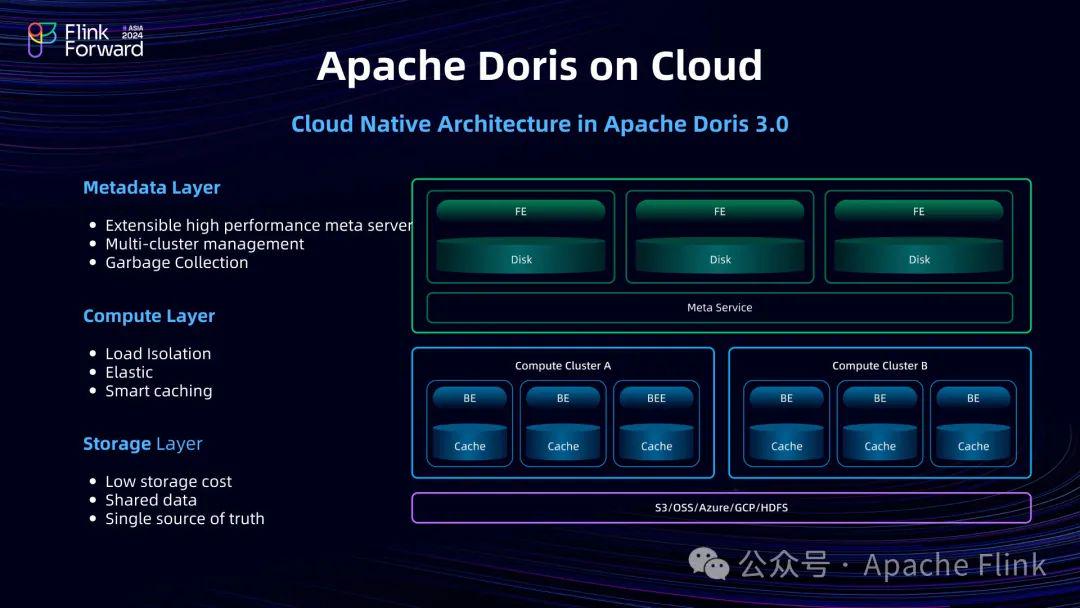
Doris 在 2024 年发布了 3.0 版本,把存算分离的架构完全开源。存算分离架构下,存储依托于对象存储服务,并引入了单独的元数据服务,以此实现了无状态的 BE 节点。可以方便的随时启停不同的计算集群满足不同的分析负载。在湖仓一体场景下,基于 Paimon 统一存储服务,用户可以使用同一份数据进行不同的数据分析处理。
社区介绍
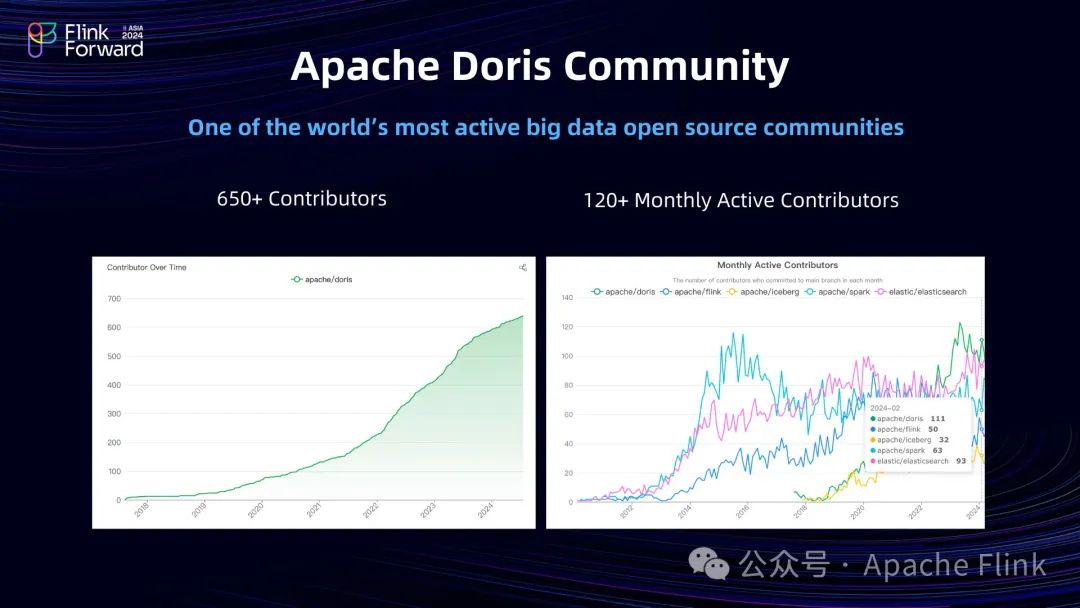
Doris 自2018年开源以来,累计有600多位的贡献者,月活的贡献者基本上平均在100位上下。并且在在国内外互联网、零售、游戏、通信等等领域都有非常多应用。后续 Doris 社区会继续与 Flink、Paimon 深入结合,提供更加完善的湖仓一体解决方案。