坦白讲,每次看性能测试排行榜,我都会下意识地先找找 Apache Doris 在哪个位置。
这次打开 JSONBench 的榜单,心情一如既往的期待加紧张。
好在结果让我松了一口气:默认配置下就能排到第三,仅次于维护方 ClickHouse 的两个版本。
不过,Doris 只能止步于此了吗?经过一系列优化后,查询时长能不能再缩短点?和 ClickHouse 的差距在哪里?
调优前后对比图镇楼,至于调优的具体思路,请一起往下看吧。
-
Apache Doris 排名 (Default)
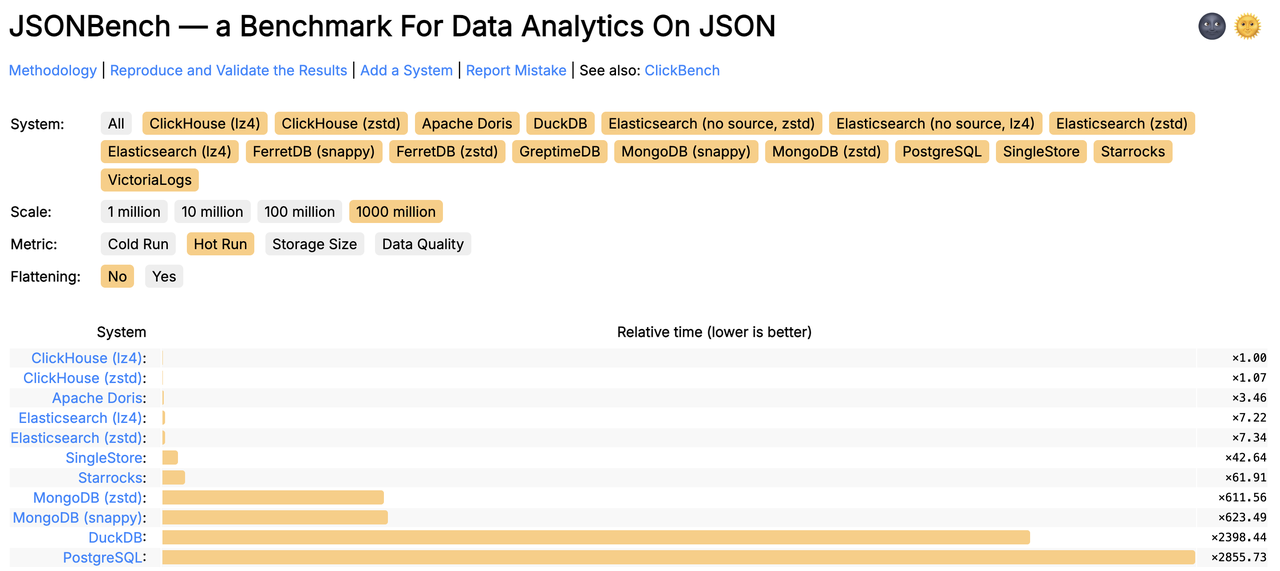
-
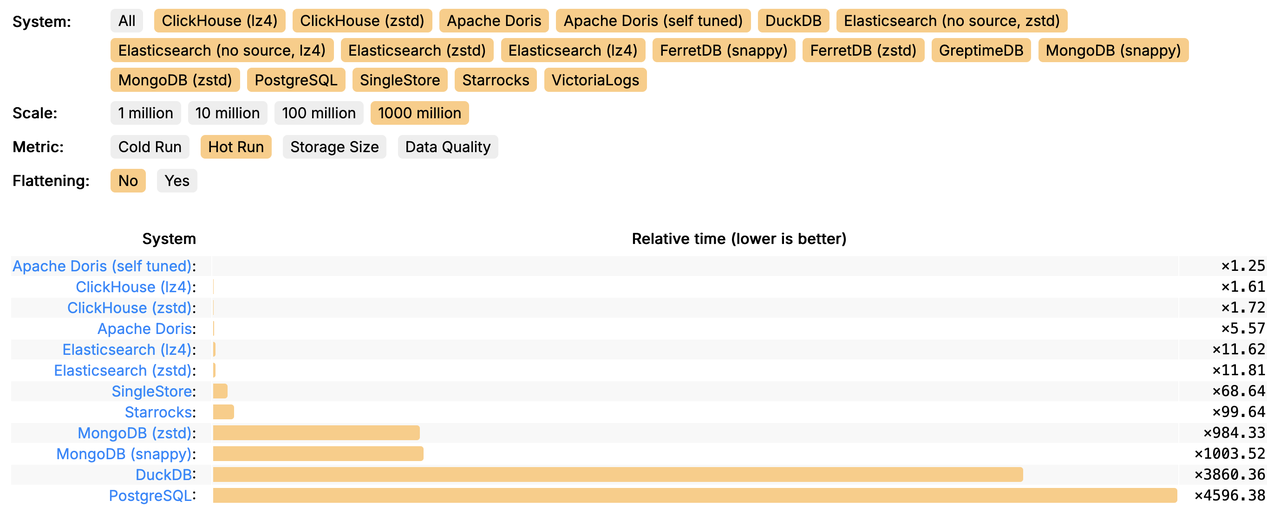
Apache Doris 排名 (Unofficial Tuned)
JSONBench 简介
JSONBench 是一个为 JSON 数据而生的数据分析 Benchmark,简单来说,它由 10 亿条来自真实生产环境的 JSON 数据、5 个针对 JSON 构造的特定 SQL 查询组成,旨在对比各个数据库系统对半结构化数据的处理能力。目前榜单包括 ClickHouse、MongoDB、Elasticsearch、DuckDB、PostgreSQL 等知名数据库系统,截至目前,Doris 的性能表现是 Elasticsearch 的 2 倍,是 PostgreSQL 的 80 倍。
JSONBench 官网地址:jsonbench.com
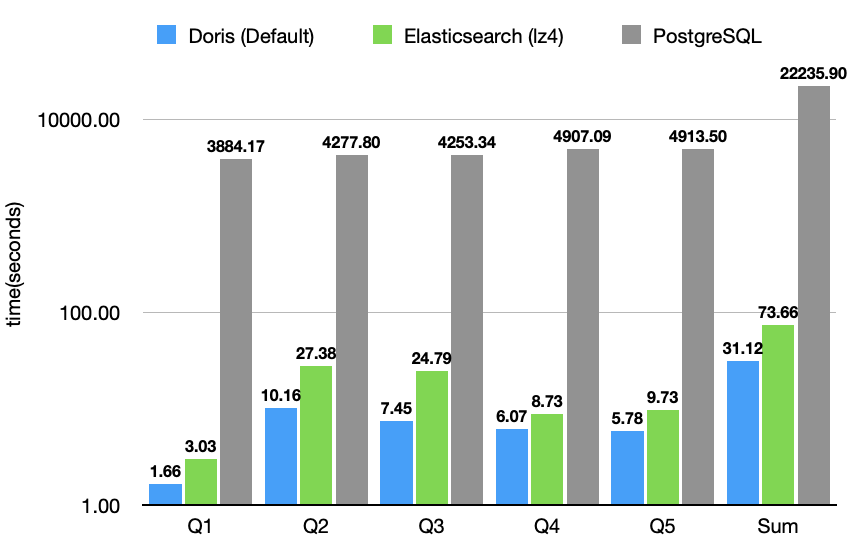
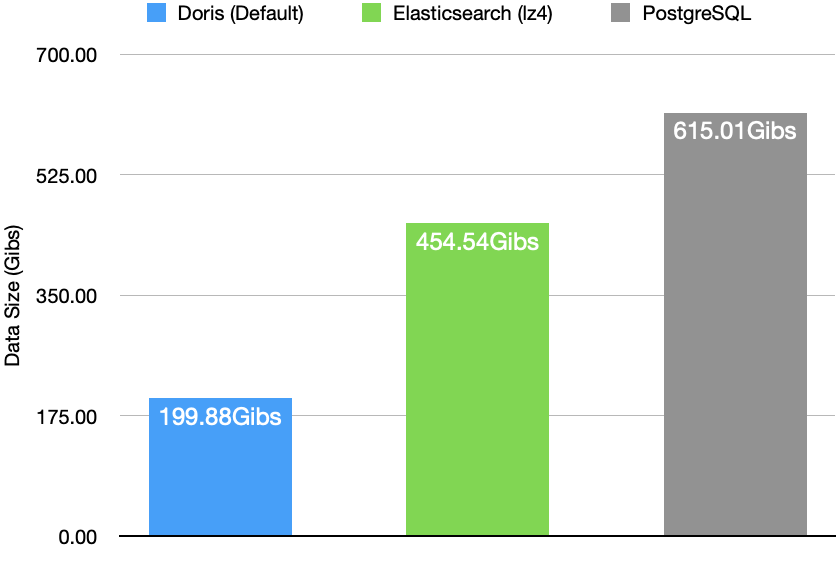
不仅在性能上 Apache Doris 领先其他同类产品,在数据集相同的情况下,Apache Doris 的存储占用是 Elasticsearch 的 1/2、PostgreSQL 的 1/3。
JSONBench 测试具体流程:首先在数据库中创建一张名为 Bluesky 的表,并导入十亿条真实的用户行为日志数据。测试过程中,每个查询重复执行三次,并且在每次查询前清空操作系统的 Page Cache,以模拟冷热查询的不同场景。最终,通过综合计算各查询的执行耗时得出数据库的性能排名。
在这个测试中,Apache Doris 使用了 Variant 数据类型来存储 JSON 数据,默认的建表 Schema 如下:
CREATE TABLE bluesky (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`data` variant NOT NULL
)
DISTRIBUTED BY HASH(id) BUCKETS 32
PROPERTIES ("replication_num"="1");
Variant 是 Apache Doris 2.1 中引入一种新的数据类型 ,它可以存储半结构化 JSON 数据,并且允许存储包含不同数据类型(如整数、字符串、布尔值等)的复杂数据结构,而无需在表结构中提前定义具体的列。Variant 类型特别适用于处理复杂的嵌套结构,而这些结构可能随时会发生变化。在写入过程中,该类型可以自动根据列的结构、类型推断列信息,动态合并写入的 schema,并通过将 JSON 键及其对应的值存储为列和动态子列。
调优思路与原理
JSONBench 榜单排名依据各个数据库系统在默认配置下的性能数据,那么能否通过调优,让 Apache Doris 进一步释放性能潜力,实现更好的性能效果呢?
01 环境说明
- 测试机器:AWS M6i.8xlarge(32C128G);
- 操作系统:Ubuntu24.04;
- Apache Doris: 3.0.5;
02 Schema 结构化处理
由于 JSONBench 特定查询中涉及到的 JSON 数据都是固定的提取路径,换言之,半结构化数据的 Schema 是固定的,因此,我们可以借助生成列,将常用的字段提取出来,实现半结构化数据和结构化数据结合的效果。类似的高频访问的 JSON 路径或者需要计算的表达式,都可以使用该优化思路,添加对应的生成列来实现查询加速。
CREATE TABLE bluesky (
kind VARCHAR(100) GENERATED ALWAYS AS (get_json_string(data, '$.kind')) NOT NULL,
operation VARCHAR(100) GENERATED ALWAYS AS (get_json_string(data, '$.commit.operation')) NULL,
collection VARCHAR(100) GENERATED ALWAYS AS (get_json_string(data, '$.commit.collection')) NULL,
did VARCHAR(100) GENERATED ALWAYS AS (get_json_string(data,'$.did')) NOT NULL,
time DATETIME GENERATED ALWAYS AS (from_microsecond(get_json_bigint(data, '$.time_us'))) NOT NULL,
`data` variant NOT NULL
)
DUPLICATE KEY (kind, operation, collection)
DISTRIBUTED BY HASH(collection, did) BUCKETS 32
PROPERTIES ("replication_num"="1");
除了可以减少查询时提取数据的开销,还可以用展平出来的列作为分区列,使得数据分布更均衡。
需要注意的是,查询的 SQL 语句也要改为使用展平列的版本:
// JSONBench 原始查询:
SELECT cast(data['commit']['collection'] AS TEXT ) AS event, COUNT(*) AS count FROM bluesky GROUP BY event ORDER BY count DESC;
SELECT cast(data['commit']['collection'] AS TEXT ) AS event, COUNT(*) AS count, COUNT(DISTINCT cast(data['did'] AS TEXT )) AS users FROM bluesky WHERE cast(data['kind'] AS TEXT ) = 'commit' AND cast(data['commit']['operation'] AS TEXT ) = 'create' GROUP BY event ORDER BY count DESC;
SELECT cast(data['commit']['collection'] AS TEXT ) AS event, HOUR(from_microsecond(CAST(data['time_us'] AS BIGINT))) AS hour_of_day, COUNT(*) AS count FROM bluesky WHERE cast(data['kind'] AS TEXT ) = 'commit' AND cast(data['commit']['operation'] AS TEXT ) = 'create' AND cast(data['commit']['collection'] AS TEXT ) IN ('app.bsky.feed.post', 'app.bsky.feed.repost', 'app.bsky.feed.like') GROUP BY event, hour_of_day ORDER BY hour_of_day, event;
SELECT cast(data['did'] AS TEXT ) AS user_id, MIN(from_microsecond(CAST(data['time_us'] AS BIGINT))) AS first_post_ts FROM bluesky WHERE cast(data['kind'] AS TEXT ) = 'commit' AND cast(data['commit']['operation'] AS TEXT ) = 'create' AND cast(data['commit']['collection'] AS TEXT ) = 'app.bsky.feed.post' GROUP BY user_id ORDER BY first_post_ts ASC LIMIT 3;
SELECT cast(data['did'] AS TEXT ) AS user_id, MILLISECONDS_DIFF(MAX(from_microsecond(CAST(data['time_us'] AS BIGINT))),MIN(from_microsecond(CAST(data['time_us'] AS BIGINT)))) AS activity_span FROM bluesky WHERE cast(data['kind'] AS TEXT ) = 'commit' AND cast(data['commit']['operation'] AS TEXT ) = 'create' AND cast(data['commit']['collection'] AS TEXT ) = 'app.bsky.feed.post' GROUP BY user_id ORDER BY activity_span DESC LIMIT 3;
// 使用展平列改写的查询:
SELECT collection AS event, COUNT(*) AS count FROM bluesky GROUP BY event ORDER BY count DESC;
SELECT collection AS event, COUNT(*) AS count, COUNT(DISTINCT did) AS users FROM bluesky WHERE kind = 'commit' AND operation = 'create' GROUP BY event ORDER BY count DESC;
SELECT collection AS event, HOUR(time) AS hour_of_day, COUNT(*) AS count FROM bluesky WHERE kind = 'commit' AND operation = 'create' AND collection IN ('app.bsky.feed.post', 'app.bsky.feed.repost', 'app.bsky.feed.like') GROUP BY event, hour_of_day ORDER BY hour_of_day, event;
SELECT did AS user_id, MIN(time) AS first_post_ts FROM bluesky WHERE kind = 'commit' AND operation = 'create' AND collection = 'app.bsky.feed.post' GROUP BY user_id ORDER BY first_post_ts ASC LIMIT 3;
SELECT did AS user_id, MILLISECONDS_DIFF(MAX(time),MIN(time)) AS activity_span FROM bluesky WHERE kind = 'commit' AND operation = 'create' AND collection = 'app.bsky.feed.post' GROUP BY user_id ORDER BY activity_span DESC LIMIT 3;
03 Page Cache 调整
调整查询语句后,开启 profile,执行完整的查询测试:
set enable_profile=true;
进入 FE 8030 端口的 Web 页面,找到相关 profile 进行分析,此时发现 SCAN Operator 中的 Page Cache 命中率较低,导致热读测试过程中存在一部分冷读操作。
- CachedPagesNum: 1.258K (1258)
- TotalPagesNum: 7.422K (7422)
这种情况通常是由于 Page Cache 容量不足,无法完整缓存 Bluesky 表中的数据。建议在 be.conf 中添加配置项 storage_page_cache_limit=60%,将 Page Cache 的大小从默认的内存总量的 20% 提升至 60%。重新运行测试后,可以观察到冷读问题已得到解决。
- CachedPagesNum: 7.316K (7316)
- TotalPagesNum: 7.316K (7316)
04 最大化并行度
为了进一步挖掘 Doris 的性能潜力,可以将 Session 变量中的parallel_pipeline_task_num设为 32,因为本次 Benchmark 测试机器m6i.8xlarge为 32 核,所以我们将并行度设置为 32 以最大程度发挥 CPU 的计算能力。
// 单个 Fragment 的并行度
set global parallel_pipeline_task_num=32;
调优结果
经过上述对 Schema、Query、内存限制、CPU 等参数的调整,我们对比了调优前后 Doris 的性能表现以及一些其他数据库系统的成绩,有如下结果:
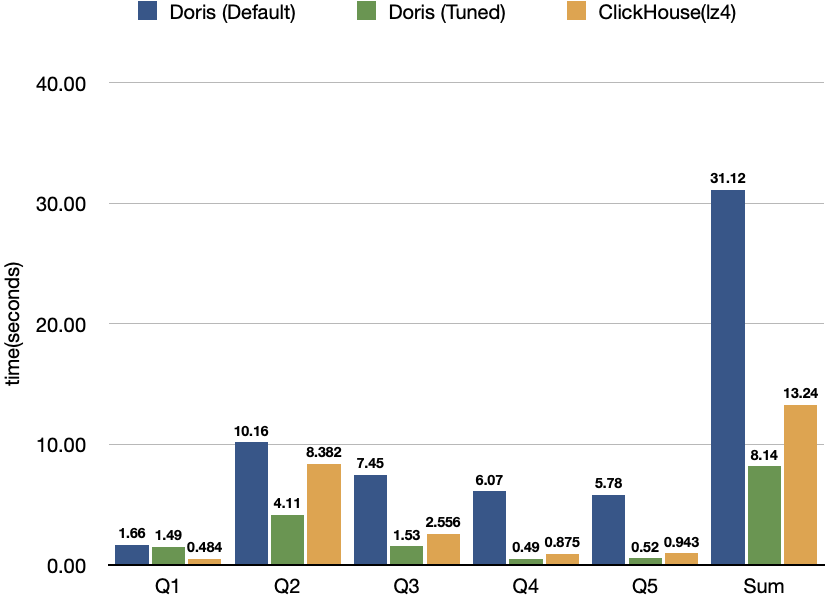
可以看到,对比调优前的 Doris,调优后 Doris 查询整体耗时降低了 74%,对比原榜单第一的 ClickHouse 产品实现了 39% 的领先优势。
总结与展望
通过对 Schema 的结构化处理、查询语句的优化、缓存配置的调整以及并行参数的设置,Apache Doris 整体查询耗时显著下降,并超越 ClickHouse。
在默认设置下,Doris 在 10 亿条 JSON 的查询耗时与 ClickHouse 仍有数秒的差异。然而,依托于 Doris 在 JSON 处理、Variant 类型支持及生成列等能力的加持,经调优后,其半结构化数据处理性能获得了进一步显著提升,并在同类数据库中表现出明显的领先优势。
未来,Apache Doris 将继续打磨在半结构化领域的数据处理能力,为用户带来更加优质、高效的分析体验,包括:
- 优化 Variant 类型稀疏列的存储空间,支持万列以上的子列;
- 优化万列大宽表的内存占用;
- 支持 Variant 子列根据列名的 Pattern 自定义类型、索引等。
推荐阅读
欢迎扫码并备注 “半结构化” 加入 Apache Doris 社区专项交流群,免费领取 100+ 企业实践案例集和 Doris x AI 更多资料、获取技术帮助、了解最新动态,并与更多开发者和用户互动。




